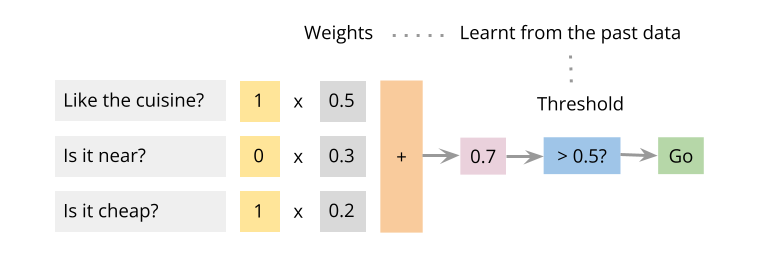
The perceptron is the simplest neural net. It operates in four steps: (1) take in several binary inputs (2) multiply each with a weight (3) add them all (4) check if it is above a threshold. If it is above, the output is 1, else the output is 0. Here is an example. Imagine you’re trying to decide whether to go to a restaurant or not. You consider several factors:
Do you like the cuisine? (1=Yes, 0=No)
Is it near? (1=Yes, 0=No)
Is it cheap? (1=Yes, 0=No)
Each of these factors has a different level of importance to you. For example, maybe you really care about the cuisine, but you don’t care as much about the distance or the price. So you could assign more weight to the factors you care about. You could represent these weights as
Cuisine: 0.5
Near: 0.3
Cheap: 0.2
These weights represent how important each factor is in your decision-making process. The perceptron works by multiplying each factor (input) by its weight, then adding up these weighted inputs. If the total exceeds a certain threshold (let’s say 0.5 in this case), you decide to go to the restaurant; if not, you stay home.
In machine learning, a perceptron can start with random weights, and learns the correct weights and the threshold based on the data it’s trained on.
Here is a super-short introduction to Softmax. Softmax is an important function in Machine Learning that converts a list of numbers into a list of probabilities. To illustrate, let us say you are deciding on a city to spend your summer vacation in, and you have three options: London, Paris, and Tokyo. Based on various factors like weather, food and transportation, you have assigned a “score” to each city.
London: 4 Paris: 2 Tokyo: 3
By using the softmax function, you can compute the probabilities of having a “good” vacation. First, calculate the exponential (e^x) of each score. Next, normalize the numbers by dividing each exponential by the sum of all exponentials.
Aspect Oriented Sentiment Analysis helps us in understanding the sentiment of a customer, regarding a specific aspect of a product. For example, the sentiment of a customer towards a mobile phone may be negative from the perspective of battery life, and positive from the perspective of sound quality. AOSA can be used to understand gather feedback about various features of a product or a service. This may be helpful in focusing on the right features, while trying to improve the product. In addition, this can be helpful in positioning as well. For example, we can use it to monitor the sentiments expressed by customers on competing products, and select the right positioning strategy: what to focus on and what not to focus on.
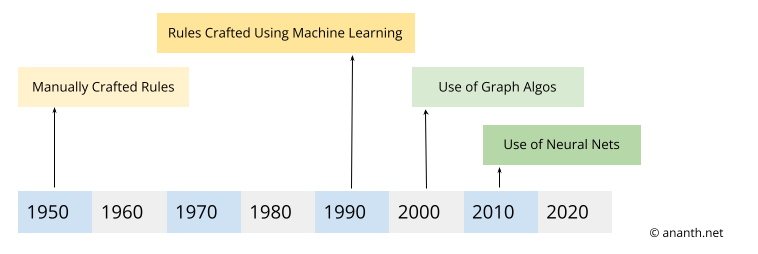
Up until recently, the text summarization was accomplished using two steps. #1 identify the key sentences #2 put them together to generate the summary. In the 1950s, researchers manually crafted rules to identify the key sentences. In the 1990s, researchers used ML algorithms to craft rules to identify the key sentences. In the 2000s, researchers used graph algorithms to identify key sentences, after representing the text as a graph! In the 2010s, researchers used neural networks to identify the key sentences. From 2017 and onwards, researches having been using a neural network architecture called Transformer to generate new text that amazingly summarizes the original document.
In the paper “Thumbs up? Sentiment Classification using Machine Learning Techniques.”, Pang et al introduced the idea of sentiment analysis using a Naïve Bayes classifier. The key idea is to combine the probability of occurrence of the words in positive and negative sentiment reviews, probability of occurrence of the words across all reviews, probability of occurrence of positive or negative reviews across all reviews to determine the probability of a text being a positive or negative based on the words in the text.
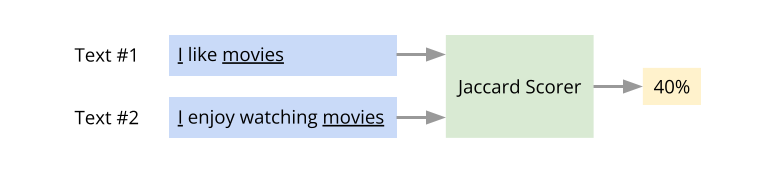
Here is a super-short intro to the concept of text similarity. There are many ways to quantify the similarity between two pieces of text. One popular approach is to use what is known as the Jaccard similarity. Consider these two sentences:
I like movies
I enjoy watching movies
The number of words that occur in both the sentences is two (“I”, “movies”). The total number of unique words across the two sentences is five (“I”, “like”, “movies”, “enjoy”, “watching”). Here, the Jaccard similarity score = 2/5. That is, 40% similarity. The idea of text similarity is has several applications. For example, given a question and a collection of sentences that are potential answers to the question, the most likely answer to the question is the one with the highest similarity score.
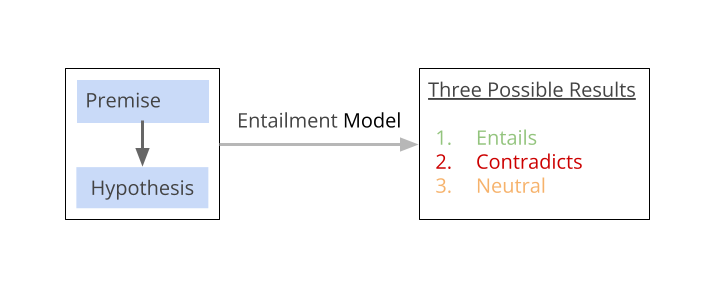
Text entailment is a problem in NLP (Natural Language Processing). Here the task is to determine if one piece of text, (aka premise) logically implies another piece of text (aka hypothesis). There are three possible outcomes from a Text Entailment analysis. The hypothesis may be entailed, contradicted or neutral with respect to the premise.
For example, consider the premise: “The elephant is trumpeting”, and the hypothesis: “The elephant is making noise”. In this example, the hypothesis “The elephant is making noise” can be logically inferred from the premise “The elephant is trumpeting”. So, the relationship between the premise and the hypothesis is “entailment”.
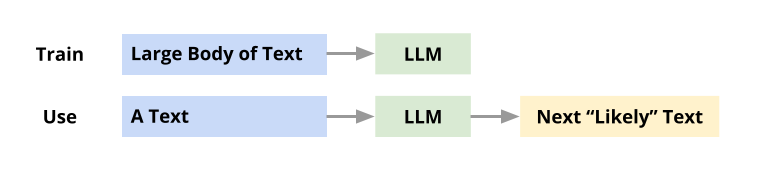
A Large Language Model aka LLM is a Machine Learning model trained with massive amounts of text. Using the “knowledge” gained from training, this model can generate new text, for any given prompt, You can think of it as a student who has read many books and can write an essay on any topic that you ask him or her to write about. In 2017, a new deep neural architecture called Transformer was invented by researchers. This architecture is the key breakthrough that resulted in powerful LLMs.